WILLIAM O’NEIL 高级工程师 陆强
WILLIAM O’NEIL(威廉欧奈尔),成立于1963年,致力于为投资机构和投资者提供投资建议和独立调研报告,目前已服务超过500家世界顶级投资机构。
我所在的是威廉欧奈尔信息科技上海有限公司,团队负责公司所有量化基金产品的业务,同时进行所有数据相关的技术研发。

1. 我们用 DolphinDB 做了什么
目前我们使用 DolphinDB 处理所有的时序数据,主要进行因子研发、中高频数据处理和 tick 级流数据处理。每天的新增数据量在1000万~5000万条级别,如果存为 CSV 文件的话,总共为4~5 GB。
1. 1 因子研发
我们结合财报和日线数据衍生出大量因子,然后使用 DolphinDB 的分布式存储、分布式计算和实时流计算等功能进行因子的存储、计算和建模。在使用 DolphinDB 进行因子研发的过程中,我们可以快速处理高达 PB 级别的数据集,利用内置的多范式的编程语言,高效开发出不同风格的因子。在计算得到一些因子后,我们可以再次使用 DolphinDB 实时计算产生基于这些因子的衍生因子,投研效率得到极大提升。
此外,我们使用 DolphinDB 进行因子评估来测试因子的有效性。之前我们使用 Python 加上某国外知名云服务商的数据库进行因子回测,在使用 DolphinDB 之后,发现 DolphinDB 也提供了一些高效的回测工具。比如通过一个 replay 函数,我们就可以模拟真实的生产环境,通过模拟回放的方式将数据注入到流计算框架中,方便之后的回测计算。在这个过程中,我们可以使用不同的回放形式,并且通过设置不同的回放速率进行匀速、倍速或者极速回放,还可以将多个表的数据回放到同一张表中,总体来说使用非常方便。未来随着项目的推进,我们计划将这块业务逐渐迁移到 DolphinDB 中。
1.2 处理中高频数据
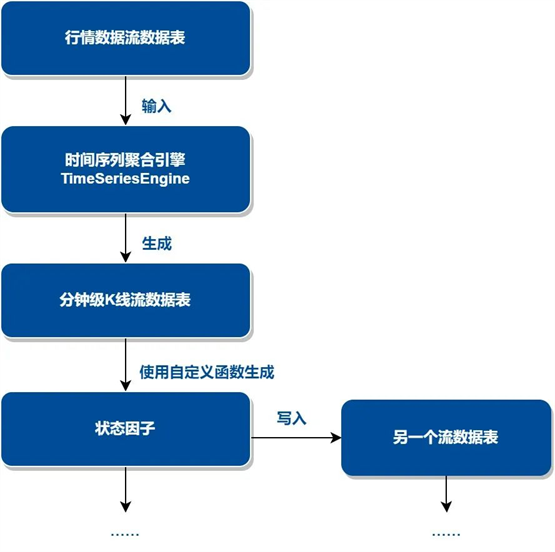
目前我们团队专攻中高频数据,这块的数据量非常庞大,历史数据大概在 TB 级别。在使用 DolphinDB 处理高频数据时,我们会对输入的行情数据使用时间序列聚合引擎生成分钟级 K 线,然后根据分钟级 K 线使用自定义函数生成状态因子,同时将输出结果指向另一个流数据表以方便之后的其他计算。在 DolphinDB 的助力下,我们实现了日线数据的高效处理,并且将研究的数据精度推进到分钟级,在降低开发成本的基础上极大提升了研发效率。
1.3 搭建 tick 级数据流架构
我们团队在去年搭建了一个处理 tick 级数据的数据流架构——使用 Kafka 连接数据流,然后传到 DolphinDB 中进行计算分析,最后得到所需数据。该数据流框架能够实时产生我们需要的市场信号。
在我看来,只要把 Kafka 接数据流这步做好,后边的很多事情并不需要操心。因为 DolphinDB 提供了非常成熟的实时流计算框架,其中最核心的部件是流计算引擎和流数据表。我们通过流数据引擎进行时间序列处理、横截面处理、窗口处理、表关联和异常检测等操作。同时可以将流数据表作为简化版的消息中间件,实现数据的发布和订阅。在投研阶段封装好的基于批量数据开发的因子函数,可以无缝投入实际生产,实现批流一体,加速开发进程。目前 DolphinDB 的延时可以控制在毫秒级,这完全满足了我们的需求。
2. 回顾数据库选型
之前我们主要研究中低频数据,使用某国外知名云服务商来存储数据,然后用 Python 进行分析计算。当公司有处理高频数据的需求时,我们发现这套系统并不能满足对数据处理的理想需求,尤其在数据分析方面,这套系统的反应速度非常慢。
于是我们在市面上寻找匹配公司需求的新产品,希望这款产品能够实现高效处理时序数据,并且方便未来扩展。
经过一番市场调研与产品性能测试,我们在选型会议上讨论了三套方案。
第一套方案是 KDB+。由于 KDB+语言晦涩,学习成本过高,这套方案并没有被采纳。
第二套方案是 NoSQL Cassandra。经过讨论,这套方案需要额外招人进行系统的重构搭建,并且后续需要专人进行维护。这会极大增加成本,所以并没有采用。
第三套方案是 DolphinDB。当时是21年初,市面上已经出现了金融行业处理时序数据“非 KDB+即DolphinDB”的两家争霸趋势。我在会议上对照 KDB+的算法例子做了一些 DolphinDB 的性能测试,然后展示了同样的例子使用 DolphinDB 语言来写,脚本明显会变得更加简洁。在一些例子中,DolphinDB 的性能超越了KDB+。当时基金经理们大多熟悉 KDB+,我在会议上做完演示后,他们也非常惊讶于 DolphinDB 的优秀性能。
最后在方案表决时,DolphinDB 以压倒性优势胜出。
3. 对 DolphinDB 的评价
使用 DolphinDB 已经有一年多了,让我印象最深刻的就是它的高性能、易上手与及时支持。
高性能
在性能方面,DolphinDB 可以对实时数据进行快速地计算与分析,实现毫秒级的响应速度,完全满足了我们高效处理时序数据的需求。
易上手
在学习成本方面,由于 DolphinDB 的脚本语言类似 Python,同时提供了很多官方的技术教程,我认为DolphinDB 是非常好上手的。如果是一个有着 C 或 Python 开发经验的同事,只需要2周、最多1个月的时间,这位同事就能对布置的项目实现上手开发。
及时支持
DolphinDB 技术支持团队的响应速度非常好。除过一些日常的技术交流,在和技术支持团队沟通的过程中,我会反馈一些 DolphinDB 原本不提供的接口或者函数的开发需求。不到一个月的时间,我发现之前提到的需求会随着 DolphinDB 的新版本同时上线,这样快速且及时的反应速度极大地帮助了我们的研发生产。
4. 文章最后
使用 DolphinDB 给我们的业务带来了极大的改善。作为一家跨国公司,我们在与国外的同事交流时,也会向他们推荐性能优秀的时序数据库 DolphinDB。衷心希望 DolphinDB 能够越做越强,未来在国际上打出更高的知名度!
